How it was made: Building Whally

This is the technical “behind-the-scenes” story of how we built Whally, our take on modern management software for schools and childcare centers. If you’re a nerd interested in the design and architecture of distributed multitenant SaaS products, read on! If the preceding sentence appears to be gibberish, you may get more joy by reading about Whally’s features, trying it live in the demo playground, or going for a nice walk instead.
The idea for Whally was conceived after several years working with educators to start, grow, and operate a large family of Montessori schools. We noticed what most school administrators already knew: the existing software options weren’t great. There were several incumbent solutions but none of them really met the bar for truly excellent school operations (or sometimes even the basic qualities of modern software).
Hence the motivation for Whally: to get better software into the hands of school administrators operating any type of educational organization, at any scale.
Wherefore art thou, Whally?
The aim of Whally is to enable educators to run great schools and childcare centers. Success will be measured by whether, in fact, the following things occur:
- Real schools use Whally daily to be better than before
- Real staff have a better daily experience in their work than before
- Real students have a better educational experience than before
- Real parents have a better customer experience than before
- Real business value is delivered in terms of operational excellence and economics
- This remains true as scale increases
But these are wishy-washy qualitative assertions. Let’s translate to more concrete technical goals:
- Highly customizable and trustworthy data platform
- Integration-friendly, comprehensive, transparent API; API-first design
- Real-time and observable: all activity in the system reflected everywhere immediately and consumable for useful things like user awareness and task automation
- Super-fast performance in all respects, both for user experience and integrated systems
- High availability and reliability
- Agile and maintainable development that responds to customer feedback
- Cost-efficient
Perhaps not the least ambitious to-do list ever 😁. Where to start?
A home in the clouds: Microsoft Azure
The first thing to decide was where Whally should live, virtually speaking. Despite our homage to the narwhal, the ocean had to be ruled out due to lack of datacenters (though this is changing). Obviously, some cloud or other was in order.
Microsoft Azure was an easy choice. We had prior experience successfully building and hosting a variety of SaaS with Azure, so it offered both proven performance and familiarity. All the infrastructure that would be needed to build Whally to its ambitious spec was present in Azure. So, there’s no suspense to relate about deliberating between competing clouds. Azure is awesome, so we used it.
Building the app: .NET, ASP.NET Core, Vue
The next task was to choose a stack for building the app. We wanted Whally to be really fast, secure, and to be productive to develop, deploy, and host. We find the combination of ASP.NET Core on top of the latest incarnation of .NET Core to satisfy all these desires. .NET continues to improve both in features and performance with each release and has a solid track record for security and long-term support. C# is a joy to use as a language that continues to get new features and refinements.
As a web application framework, ASP.NET Core checked all our boxes to build a modern, robust REST API that is the foundation of Whally. The MVC model is also used extensively for serving web content. We've yet to find anything that isn’t straightforward to achieve in ASP.NET Core — whether API design, dynamic or static content, advanced security, or highly functional dev ops practices.
In terms of approach, Whally was designed and built following the principle of being API-first, which means that everything Whally does is performed through a public API operation. This ensures Whally is a truly interoperable platform by virtue of its API presenting publicly all its capabilities. Users get the benefit of an awesome, full-functional API that can achieve anything that can be done in the app itself. Whally’s Vue app, therefore, is just a public API client and the fundamental system interface is the API, not the app’s user interface.
Finally, we wanted Whally’s user experience to be responsive, fast, and to work anywhere without the hassle of app store downloads. Enter Vue, a wonderful front-end framework that is super-productive, friendly, and robust. Vue pairs swimmingly as a front end with an ASP.NET Core API backend and has an active, growing ecosystem. As with ASP.NET Core, we’ve yet to find anything that can’t be achieved with Vue — whether single-page progressive web app or embeddable widgets.
Hosting the app: Azure App Service
So, you have a shiny new app. Where to host it? In Azure, there are several options including virtual machines and containers. We chose Azure App Service, a mature and fully managed platform that removes the hassle of running web apps. App Service does a good job of marrying simplicity with power when you need it. We simply push code, and it deploys via Azure DevOps directly into App Service. No servers to patch, no complicated orchestration configuration, just code to web. As Whally grows and needs more resources, that’s a matter of clicking a button to scale up seamlessly – no migrating between servers.
App Service also works great for running background worker processes implemented from IHostedService in ASP.NET Core. Whally uses a combination of public-facing web instances and internal worker apps all hosted on App Service. In either case, the deployment, hosting, and operations processes are the same.
Storing the data: Cosmos DB
The next decision was where to store the data. If uncommonly sophisticated treatment of data would be a strength of Whally, it stands to reason the choice of database is fundamental to achieving that outcome. Recalling the aforementioned list of goals, such a database would need to be highly flexible, performant, resilient, observable, and cost-efficient while facilitating secure multitenant isolation.
Azure Cosmos DB is all of these things for Whally. In particular:
- Schema-free design allows Whally to store dynamic, user-extensible data formats naturally
- Low latency SLA provides consistent, excellent performance
- Global turnkey distribution means Whally data can be accessible and instantly replicated anywhere in the world. This is fundamental to Whally’s highly available architecture.
- Cosmos DB’s partitioning can be leveraged to achieve secure multitenant storage in a cost-effective manner
- Change Feed provides a reliable, observable stream of data events that drive Whally’s real-time features
- As a fully managed database as a service, Cosmos allows us to focus on Whally and delegate operations and maintenance to Microsoft
- The excellent .NET SDK facilitates robust, performant and secure data operations
Further down, we'll discuss how all this was accomplished in the case of Whally.
Big picture: architecture
We strive for simplicity with Whally but still ended up with a fair number of moving parts. You can see some of those below. Everything depicted resides in Microsoft Azure. Not everything is shown, but we see the most important bits here and see how the various services compose into the overall system.
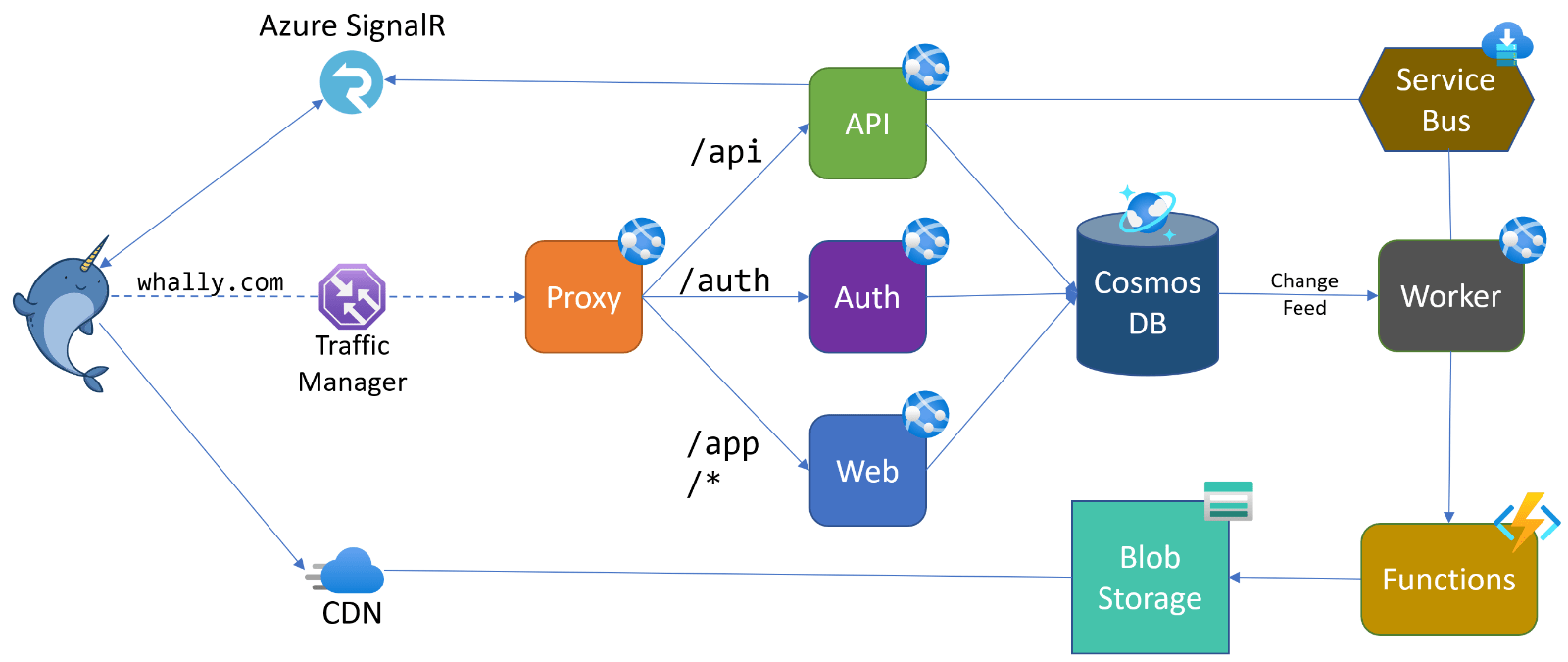
Notes on the components:
- Central to the architecture is Cosmos DB, which provides a common data backplane for each of the app instances. It also surfaces the Change Feed that is processed by the worker to broadcast real-time updates.
- Proxy fronts the public-facing apps and exposes a unified URL namespace behind whally.com. This allows separating the app instances for separate deployment and configuration without exposing this fragmentation to users or API consumers. Proxy also provides a security function by rate-limiting and blocking bad requests
- Traffic Manager routes users to their nearest healthy Whally datacenter. In the event of a regional failure or scheduled maintenance, users will automatically re-route to a secondary Whally region.
- Azure CDN serves static content and blob storage assets quickly from the nearest cache, taking load off the web app and making users happy
- Azure SignalR provides real-time broadcasting of events to connected clients. Using this managed service offloads the many client connections and associated overhead from Whally itself. The API app acts as the hub go-between and sends messages arriving from the worker’s change feed processor.
- Azure Service Bus is used for reliable queuing and internal event publishing. Any app instance can push events onto a queue and listen for events to take actions like updating caches
- Azure Functions is used for tasks that require asynchronous heavy lifting like image optimization. It’s also useful as a reliable scheduler for triggering recurring distributed actions.
Resilience and speed: multiple regions
The architecture above is that for a single instance of Whally in a specific location/region. What happens if there’s a problem in that location like a power outage or other natural disaster? Or what if Whally engineers need to do some major maintenance and take things offline? The typical way to handle this is a message to customers saying “sorry, the thing you’re paying us for isn’t working right now. We’ll try to make it work again at some point”. We find such messages to be embarrassing and unnecessary, and in order to avoid them the Whally architecture is deliberately designed for simultaneous operation in multiple regions, as shown below.
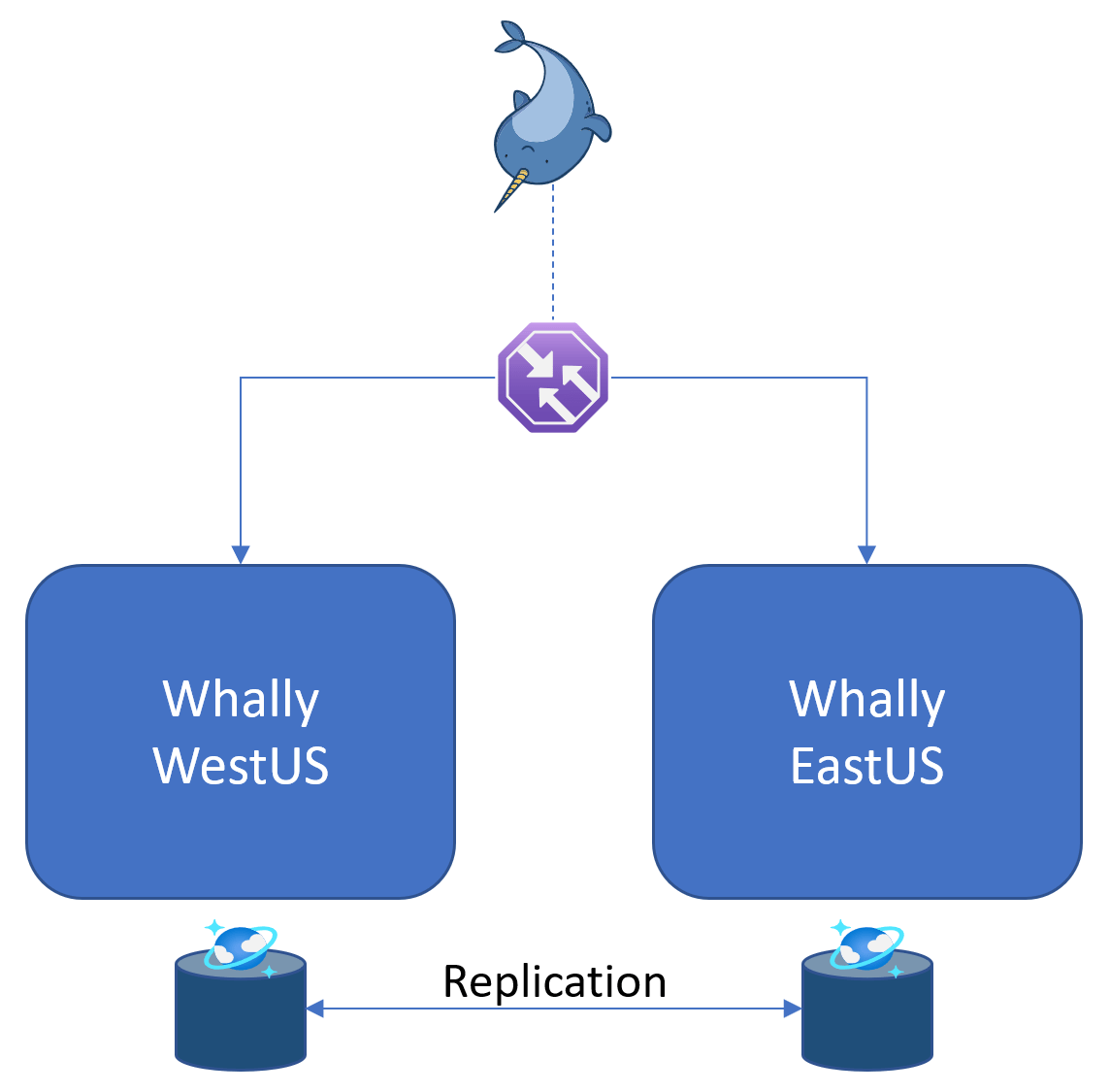
There are multiple interchangeable clones of Whally running in multiple places, for example the western US and eastern US. This means that even if one of the regions had a zombie attack and went offline, the other regions would continue to function, and users would be automatically re-routed away from the failed region. It also allows a region to be proactively taken out of service by Whally engineers without disrupting anyone or sending any embarrassing messages about their plans for Saturday at 2am.
A nifty secondary benefit of Whally’s multi-region approach is speed. Users automatically connect to their closest region through Traffic Manager, so Sally in Baltimore connects to East US and Jacinda in Sydney to Australia East. They each enjoy the quick operations afforded by their nearby connections and avoid waiting for requests to travel thousands of miles.
This is made possible by the native replication of Cosmos DB, which keeps data in sync across every global replica. Whally just needs to read and write data, and Cosmos DB takes care of making sure it is updated very quickly across the globe.
Real-time updates
As the number of users grows and especially as more collaboration happens across teams, it's essential that the data we work with is fresh. In the old days, we formed the bad habit of clicking refresh to make sure we saw the latest before making a change. Some apps started doing this under the covers, repeatedly polling the server for changes. But the world has learned how to solve this problem the right way, and that way is called real-time streaming.
Whally’s goal is that what you see is always current. That means changes made by others need to be reflected immediately in your view. But we don’t want to waste user or server resources on frequent polling.
Cosmos DB and SignalR offer a nice solution here. With its Change Feed, we can consume from Cosmos a continuous stream of events corresponding to each change in a data item. This change can then be converted to a notification message sent to all clients through SignalR, which maintains a two-way connection with all active app sessions. Thus, every interesting change can be broadcast to appropriate clients who can update their state accordingly.
The components of this setup are shown below. A background Worker app continuously consumes the change feed, inspects the changes to filter for interesting events, and publishes onto a queue. The SignalR hub receives each event and sends as a notification to individual clients or groups as appropriate to context and security. SignalR in this case is the hosted service by Azure, which offloads connection maintenance from Whally’s app instances.

This results in immediate updates that keep everyone in sync. In practice, Whally users see updates appear within 2 seconds of changes made anywhere.
Tenant isolation: securing customer data
Whally is implemented as a multi-tenant software-as-a-service platform, which allows economical sharing of infrastructure costs between customers. With any such system, the first and most important question is: how is data isolated and access enforced for customers within their own tenant boundary? We must prevent users from crossing tenant boundaries when accessing data and also from disrupting other tenants by excessive resource usage (“noisy neighbor” problem).
With Cosmos DB, there are three general options to isolate tenant data:
- Database per tenant: provision each customer a separate database and perform queries for a user against their dedicated tenant database
- Container per tenant: provision each customer a separate logical container and perform queries for a user against their tenant container
- Logical partition(s) per tenant: customers share a database and logical container but are restricted to queries within logical partitions which correspond to their tenant
There are pros and cons to each option. Database-level isolation provides clear separation in all aspects and inherent noise isolation because each database has dedicated throughput. Container-level isolation also provides an explicit boundary between tenants and can be configured for shared or dedicated throughput models to govern usage.
But both of the above increase monetary and application costs. Each database or container comes with a fixed cost, adding operating expense for each customer. Application code is arguably made more complex to keep track of mapping tenants to their database/container, and cross-tenant queries for backend management are prevented altogether.
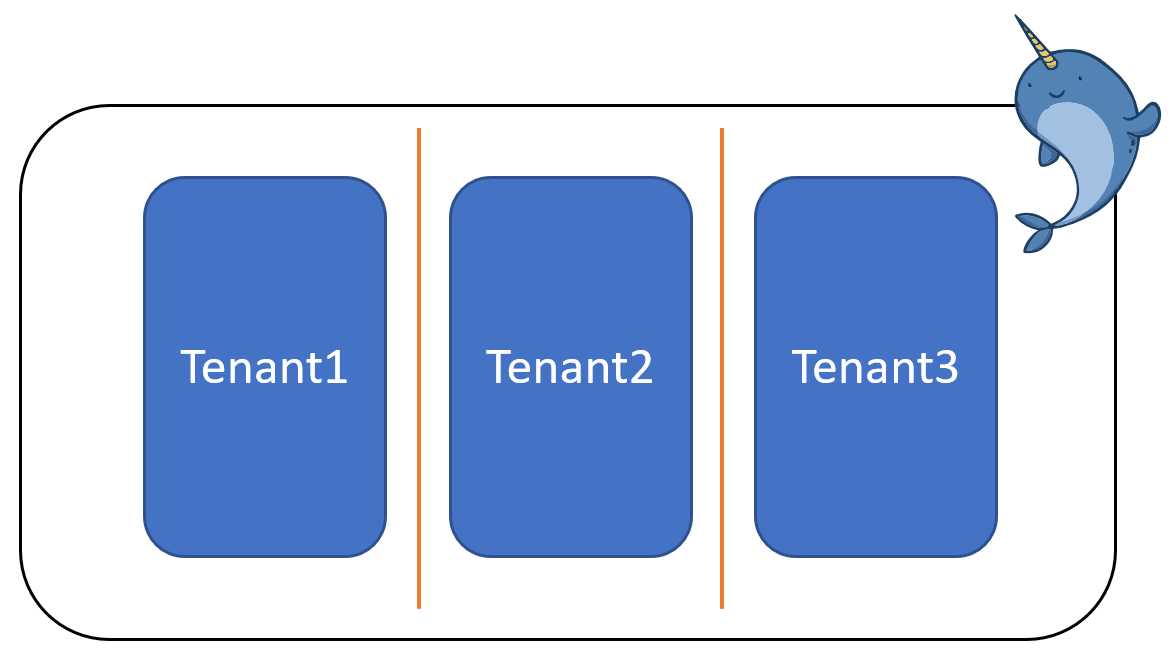
With Whally we opted to use logical partitioning for tenant isolation. This provides several advantages:
- No marginal per-tenant cost: tenants can be added for ~free
- Cross-tenant queries: for backend management, we can efficiently query for aggregate data across all tenants within a single query
- Simplified design: a single database and container to secure, back up, maintain
- Straightforward, verifiable app logic: constrained code paths always query with a partition key securely derived from the user’s tenant association
- Opportunity to perform noisy-neighbor control in application layer where context of requests is available and understood
To achieve this, we implement a partition key strategy that combines the tenant ID as a prefix and a data type as a suffix. In this manner, every item falls within a partition tied to a specific tenant. The type suffix further divides the tenant data across multiple partitions, which helps query performance and limits the storage size of data in any given partition.
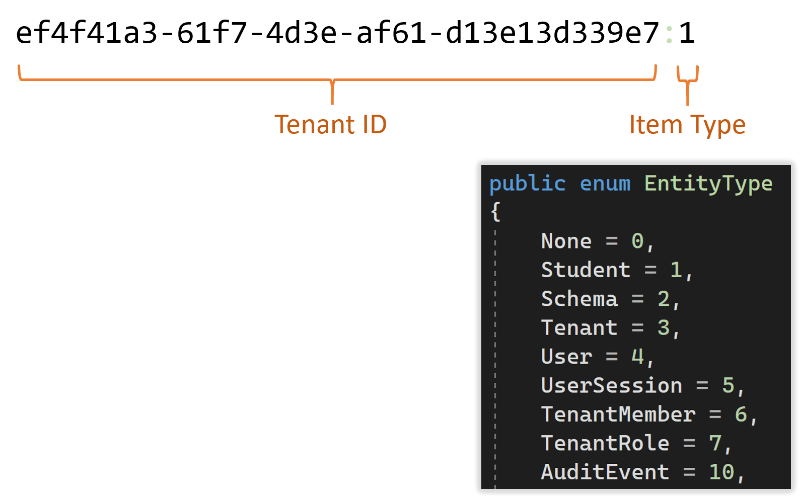
Given this partition key structure, we can guarantee that any query issued using a valid partition key will land in a partition with data belonging to the associated tenant. Now, we just need to ensure all queries are performed with a valid partition key which corresponds to the user of the request context.
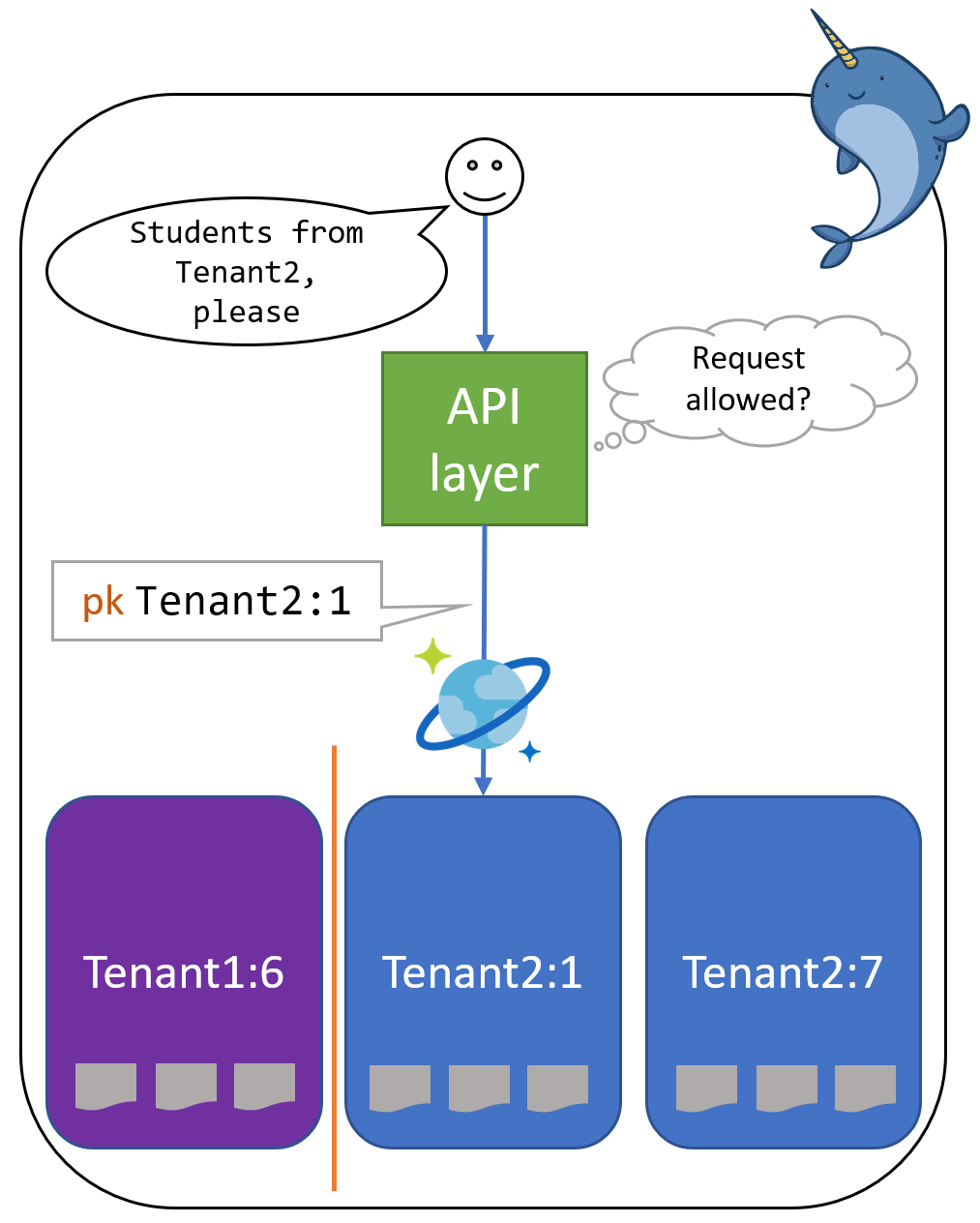
This is straightforward to extract from a user’s authenticated session claims. Suppose Randy is the requester and is authenticated for access to Tenant2. We use this when constructing queries on Randy’s behalf. Hence, no query resulting from Randy’s request can ever obtain data outside Tenant2.
Container layout
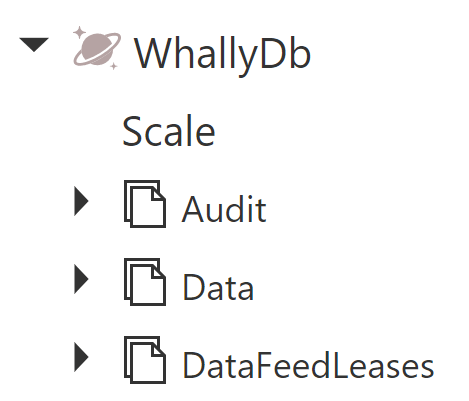
The Cosmos DB database layout under this strategy is surprisingly simple: just a few containers to configure and manage. Because containers are logical rather than physical and scale horizontally, there is no practical limit on capacity growth. Above all, this results in a simplicity of design that’s understandable and straightforward to support.
The containers include:
- Data: all data items belonging to tenants and the system itself
- Audit: history records for all audited data items. Discussed below.
- DataFeedLeases: maintains the change feed which observes the Data container
This structure can be easily mirrored for our demo playground environment to ensure demo data is segregated from production.
Whodunit? Keeping audit history
To be a serious data platform worthy of use in even the most rigorous organizations, Whally needed to provide accurate records of its own changes. In particular, this means a proper audit trail identifying who, what, when for every data change.
Cosmos DB doesn’t itself perform this function but auditing wasn’t hard to achieve in the application layer. For every data operation resulting in a creation, update, or deletion of an item, we store an associated audit record in the Audit container. Using a separate container for audit items is helpful to unambiguously enforce immutability in the application layer to prevent accidental or intentional tampering/deletion. It’s also helpful that the Audit container isn’t observed for change feed purposes, so writing items here doesn’t incur needless overhead of a triggered change event.
The audit items themselves are straightforward, identifying the user responsible for the change, the time it occurred, the before/after state of the changed fields, and version ETags associated to the before/after item state. Storing the ETag values gives us a representation of a series of item versions that can be chained to understand how an item’s state evolved over multiple changes. We also use this mechanism to automatically resolve write collisions where two users attempt to change an item at the same time. Since we know what fields changed previously, we can determine if the latest changes conflict or can be merged, preventing a Precondition Failed error response.
Custom fields for user-defined data
A central goal with Whally was flexibility and customization. In our view, software should try where possible not to impose assumptions on users, especially when those assumptions don’t make sense for their needs. Perhaps more than anywhere else, this applies to structuring application data. A frequent and naïve approach is to define a data model that includes fields for every possible need across many customer types. Thus, Montessori schools are forced to use the same interface and data formatting as childcare centers or after-school programs, even though each of these may have quite different needs for storing information.
Whally’s approach is to allow users to configure their own data storage in a way that fits their purposes. In practice, this means few “out of the box” fields and freedom to add as many specific custom fields as needed. And adding custom fields needs to be simple, self-service, and seamless. There should be no practical limits or need to request support.
Fortunately, this is quite doable with Cosmos DB and .NET. Cosmos DB, being schemaless, doesn’t impose any expectations on data format and accepts any well-formed dynamic shape and content. It was a simple matter to add a CustomFields property to Whally’s base entity model. Any user-defined data lives under this dictionary structure and is natively indexed and immediately available to query without any modification to the database configuration.

**

But just because Cosmos DB is schemaless doesn’t mean we can’t impose a schema. Whally does just that, albeit within the application layer. Each item type with custom fields has a custom schema for that type. Using this, every data operation can be validated and normalized to guarantee data is always written in exactly the correct format. We get the best of both approaches: the freedom to change data fields on the fly, and the assurance that data stored in Whally will be well-formed and trustworthy.
Continuous deployment
To be productive implementing all the features in Whally, we needed to remove the overhead of code deployment. For this we rely on Azure DevOps pipelines that trigger a build for every code commit. These builds then trigger deployment releases into Azure App Service, either automatically or with manual approval.
Once in place, this DevOps pipeline reduces deployment to simply checking in code. We worked to optimize our build and deployment processes to get tasks to run in well under a minute, sometimes as fast as 15 seconds. With this level of efficiency, we can move at a satisfying velocity from idea to code to live feature with the confidence of validated, tested builds and safe, non-disruptive deployments.
All changes to Whally infrastructure also follow this model. The entire Whally infrastructure is defined as code in Azure Resource Manager templates. As such, the only method for making operational infrastructure changes is to modify a template which proceeds through a validated build and release process. This prevents temptation to make undocumented one-off changes directly in the portal. Transparency achieved; regret avoided.
Watch the presentation
This content and more was presented at Microsoft's Cosmos DB Conf! It goes in-depth with more specifics about design decisions and implementation tips related to Cosmos DB.
Conclusion
Building Whally continues to be a great experience. It’s hard to overstate the value of having a solid, clean foundation both in the codebase and the infrastructure upon which to continue evolving a first-class, enterprise-scale platform.
There’s more to the story than described here, but we’re happy to share. Questions or curiosities? Say hello!
Thanks for reading! 😃